|
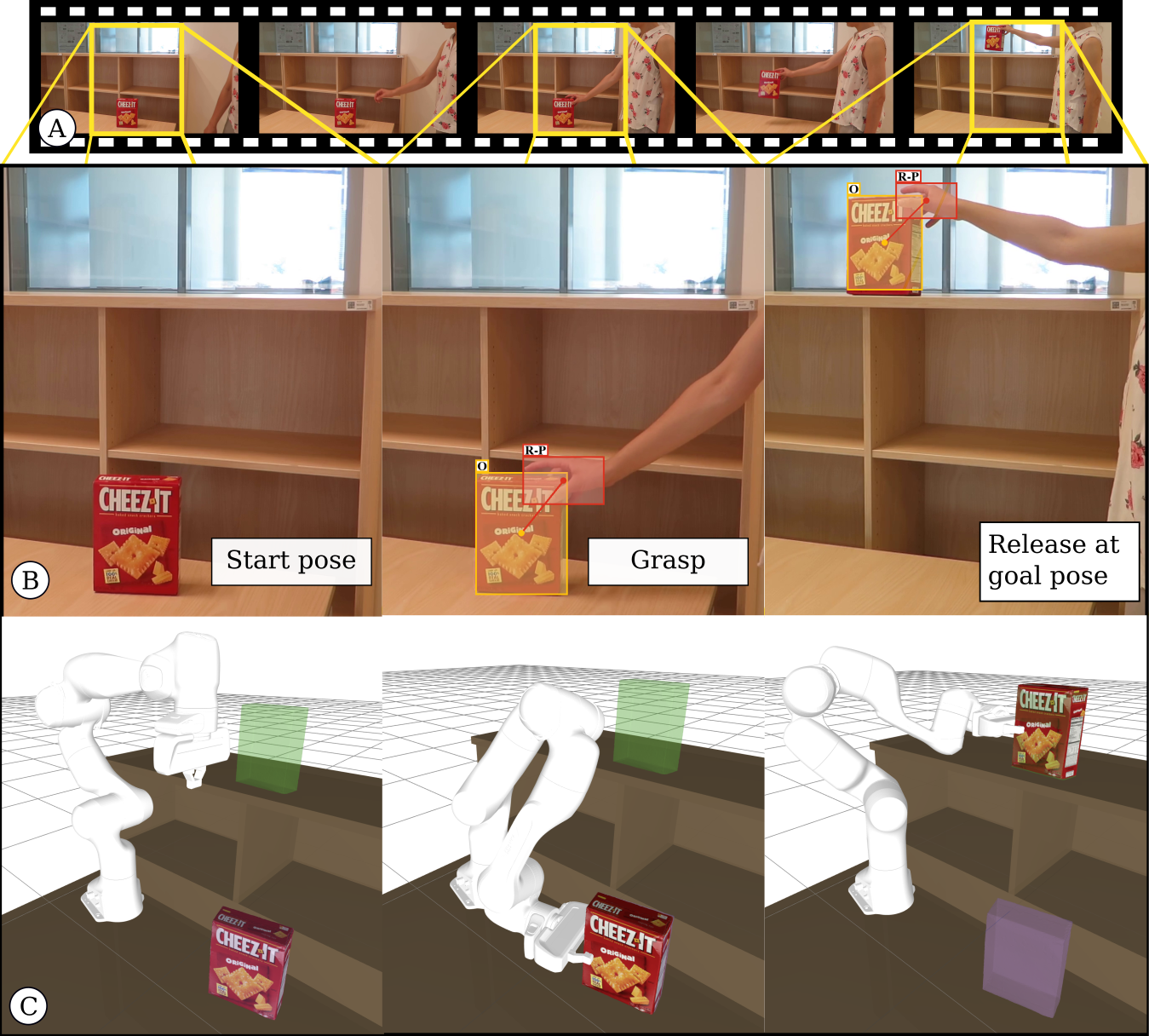
| The proposed planning approach is guided by the demonstration video (A). The video depicts a person manipulating a known object; the cheez-it box in this particular example. The video can contain several pick-and-place actions with multiple objects. Here only a short clip with only one object and one action is shown. From the video we recognize (i) the contact states between the human hand and the object, marked by red bounding boxes in (B); and (ii) the object 6D pose (3D translation and 3D rotation w.r.t camera) at the grasp and release contact states, marked in yellow in (B). The robot trajectory planned by the proposed approach is shown in (C). The start and goal object poses in (C) are shown in magenta and green, respectively. |
